The Climate Change Adaptation Digital Twin (Climate DT), implemented as part of the Destination Earth initiative of the European Commission, is operationalising a framework to produce global climate projections several decades ahead, at kilometre-scale resolution, where the impacts of extreme events and climate change are observed. At the same time, it introduces new methods for translating these unprecedented volumes of climate data into impact-sector information. One of these methodologies is the use of so-called “one-pass algorithms”, which condense and translate raw climate data into sector-relevant information while the climate projections are running.
Producing climate simulations at kilometre-scale resolution over multi-decadal timescales generates very large volumes of data, far more than conventional storage and processing workflows can easily handle. The Climate DT not only increases spatial resolution but also significantly raises temporal frequency, producing outputs at hourly intervals instead of sub-daily or monthly ones. This results in much larger data volumes than those typically produced by current climate models.
At the same time, the Climate DT aims to go beyond simply delivering raw climate model output. Traditionally, users must work with the variables that have been stored, which are often selected based on what can feasibly be archived rather than on end-user needs. In contrast, the Climate DT is designed to provide more targeted, usable climate information that is relevant to specific impact sectors. For example, statistics on wind variability for energy operators, or indicators of extreme rainfall for flood risk assessment. This shift toward tailored, user-relevant outputs requires not just storing more data, but processing it more efficiently and purposefully, and, crucially, tailoring it through co-design with selected representative users from climate-affected sectors.
While one-pass algorithms (OPAs) have been used in fields like online trading and machine learning, their application in climate science is entirely new, pioneered within the Climate DT. Here, they enable the system to condense and translate massive volumes of complex climate data into sector-specific indicators and statistics, making the outputs both technically manageable and directly relevant for climate services and decision-making.
Understanding the one-pass algorithms
In the Climate DT, the aim is not only to run advanced climate simulations, but to transform their output into impact-sector information as the simulations are running. To do this, the system integrates sector-relevant applications directly into the workflow, allowing the processing of raw climate output and the generation of actionable indicators in near real-time.
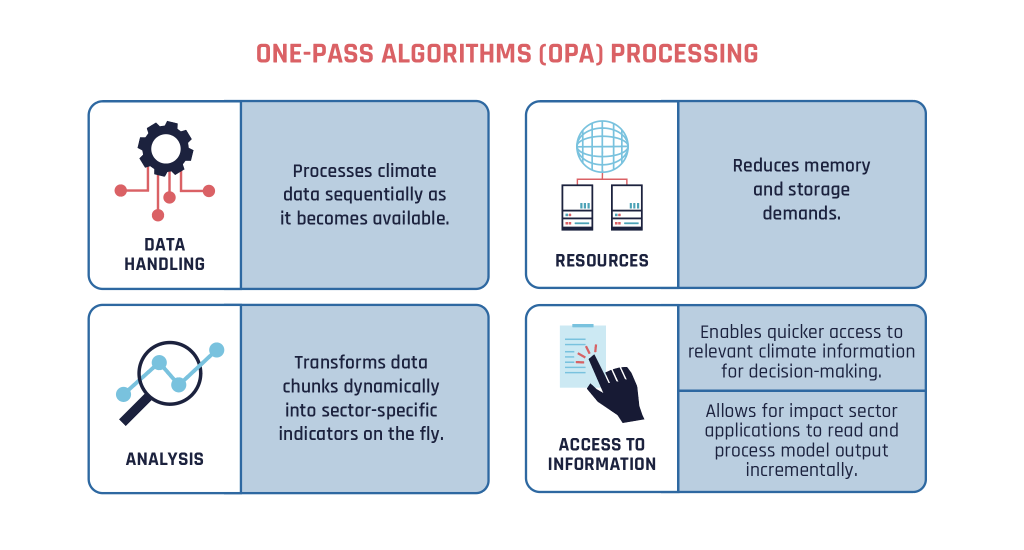
One-pass algorithms are a key enabler of this approach. These are techniques that process data sequentially, enabling the computation of statistics without requiring access to the entire dataset at once. When applied in the Climate DT, they allow applications to read and process model outputs incrementally, as the simulation produces them, rather than waiting for the full dataset to be generated and stored. This incremental processing enables the transformation of raw output into meaningful, sector-specific indicators “on the fly” during the simulation.
Here, “on the fly” means that the data is transformed dynamically during the simulation, without requiring full storage of all raw data before analysis. This approach reduces memory and storage demands, and enables quicker access to relevant climate information for decision-making.
To implement these algorithms, the Climate DT developed the One-Pass Package. It is a flexible, bespoke open-source Python toolkit that computes statistics and assists in bias adjustment of climate data using one-pass algorithms. This package enables the efficient processing and transformation of large climate datasets into sector-relevant outputs that can be used directly by climate-sensitive sectors.
Turning data into sector-specific information
Different sectors rely on specific climate statistics depending on their needs and the variables most relevant to them. In the Climate DT, one-pass algorithms are used to compute these statistics directly during the simulation process, supporting the generation of indicators that are relevant to applications across multiple domains.
The Climate DT team focuses on six core statistics that are essential for understanding both average conditions and extreme climate behaviour.
| Mean | Represents the average climate conditions (over time). |
| Standard deviation | Measures variability in climate data. |
| Minimum and maximum | Measures extreme values over different time periods, essential for capturing extreme events. |
| Percentiles | Quantify climate extremes for defined thresholds. |
| Histograms | Describe the distribution of climate variables. |
| Intensity Annual Maximum Series (iams) | Capture the highest value recorded over various temporal durations each year to assess extreme events. |
Each of these statistics can be calculated using one-pass algorithms, which operate directly on the data stream as it is produced by the climate models. This enables efficient computation without the need to store or access full datasets, and allows the Climate DT to deliver sector-specific statistics with reduced latency and lower computational resource demands.
Integration in the Climate DT workflow
The One-Pass Package is fully integrated into the Climate DT’s structured computational workflow. This workflow is automated by tools like Autosubmit, the Climate DT’s lightweight workflow manager, and runs on EuroHPC systems. This setup allows OPAs to operate continuously alongside the climate simulation, processing data as it becomes available. Designed to run on high-performance co
mputing infrastructure, the One-Pass Package can be paused by the workflow when no new data is available, ensuring that no compute resources are wasted and enabling efficient, scalable operation.
Use Case examples
WIND ENERGY
For the wind energy sector, understanding the distribution of wind speeds and capacity factors (i.e. actual potential energy) over time is crucial, as turbine power output strongly depends on wind variability. These wind speed distributions are usually represented by histograms, although generating them from km-scale climate data can require significant storage and processing resources.
One of the one-pass algorithms implemented by the Climate DT’s teams is the “t-digest” algorithm, designed to estimate distributions in a memory-efficient way while processing climate data in chunks as the simulation progresses. By integrating this approach into the simulation workflow, the Climate DT can estimate wind speed and capacity factor distributions on the fly, significantly reducing memory requirements while maintaining accuracy.
This OPA-based approach makes it possible to produce sector-relevant wind statistics continuously as the climate model runs. For example, an embedded wind energy application in the Climate DT uses one-pass algorithms to compute tailored wind energy indicators for both onshore and offshore sites, delivering information that supports long-term planning and decision-making. Wind farm operators can access these timely, tailored outputs without the need to post-process large volumes of stored model data.
EXTREME PRECIPITATION
The one-pass algorithms are also used for the HydroMet application of the Climate DT, which provides statistics, in this case the Intensity Annual Maximum Series, on extreme rainfall and future flood scenarios, by using adapted versions of applications developed by the German Weather Service (DWD) and the Helmholtz Centre for Environmental Research (UFZ).
Typically, the OPAs are used to process high spatial and temporal resolution precipitation data as it is produced, avoiding the need to store full datasets. They calculate statistics such as the maximum rainfall over specific periods (e.g. 1 hour, 6 hours, or 2 days) using rolling time windows. By integrating these one-pass algorithms into the HydroMet workflow, the Climate DT can provide information regarding extreme rainfall events and generate indicators relevant for flood risk assessment, water resource management, and infrastructure planning, all during the simulations, while keeping storage and computational costs low.
Why it matters: From climate model output to sector-relevant information
By enabling the real-time transformation of high-resolution climate model outputs into ready-to-use sector-relevant information, the newly developed One-Pass Package within the Climate DT helps manage growing data volumes while improving the relevance and accessibility of climate outputs. Through one-pass algorithms, these indicators and statistics can be generated directly during climate model simulation runs, eliminating the need for full data storage or extensive post-processing. This ensures that complex climate outputs are delivered in forms that are both manageable within technical constraints and aligned with user needs, supporting more informed, timely, and effective decision-making across sectors.
In doing so, the Climate DT moves beyond raw model output to deliver information that is ready to inform climate adaptation planning and sector-specific action.
The Climate DT, procured by ECMWF in the framework of Destination Earth is developed through a contract led by CSC-IT Center for Science and includes Alfred Wegener Institute Helmholtz Centre for Polar and Marine Research (AWI), Barcelona Supercomputing Center (BSC), Max Planck Institute for Meteorology (MPI-M), Institute of Atmospheric Sciences and Climate (CNR-ISAC), German Climate Computing Centre (DKRZ), National Meteorological Service of Germany (DWD), Finnish Meteorological Institute (FMI), Hewlett Packard Enterprise (HPE), Polytechnic University of Turin (POLITO), Helmholtz Centre for Environmental Research (UFZ) and University of Helsinki (UH).
Destination Earth is a European Union funded initiative launched in 2022, with the aim to build a digital replica of the Earth system by 2030. The initiative is being jointly implemented by three entrusted entities: the European Centre for Medium-Range Weather Forecasts (ECMWF) responsible for the creation of the first two ‘digital twins’ and the ‘Digital Twin Engine’, the European Space Agency (ESA) responsible for building the ‘Core Service Platform’, and the European Organisation for the Exploitation of Meteorological Satellites (EUMETSAT), responsible for the creation of the ‘Data Lake’.
We acknowledge the EuroHPC Joint Undertaking for awarding DestinE strategic access to the EuroHPC supercomputers LUMI, hosted by CSC (Finland) and the LUMI consortium, Marenostrum5, hosted by BSC (Spain) Leonardo, hosted by Cineca (Italy) and MeluXina, hosted by LuxProvide (Luxembourg) through a EuroHPC Special Access call.
More information about Destination Earth is on the Destination Earth website and the EU Commission website.


